In this segment you are going to learn how make a python command line program to scrape a website for all its links and save those links to a text file for later processing. This program will cover many topics from making HTTP requests, Parsing HTML, using command line arguments and file input and output. First off I’m using Python version 3.6.2 and the BeautifulSoup HTML parsing library and the Requests HTTP library, if you don’t have either then type the following command to have them installed on your environment. So let’s get started.
pip install bs4, requests |
Now let’s begin writing our script. First let’s import all the modules we will need:
1 2 3 4 | #!venv/bin/python import sys import requests import bs4 |
Line 1 is the path to my virtual environment’s python interpreter. On line 2 we are import the sys module so we can access system specific parameters like command line arguments that are passed to the script. Line 3 we import the Requests library for making HTTP requests, and the BeautifulSoup library for parsing HTML. Now let’s move on to code.
1 2 3 4 | if len(sys.argv) == 3: # Code will go here else: print('Usage: ./collect_links.py wwww.example.com file.txt') |
Here we will check sys.argv, which is a list that contains the arguments passed to the program. The first element in the argv list(argv[0]) is the name of the program, and anything after is an argument. The program requires a url(argv[1]) and filename(argv[2]). If the arguments are not satisfied then the script will display a usage statement. Now let’s move inside the if block and begin coding the script:
1 2 3 4 5 6 7 8 | url = sys.argv[1] file_name = sys.argv[2] #TODO: Make the request #TODO: Retrive all links on the page #TODO: Print links to text file |
On lines 2-3 we are simply storing the command line arguments in the url and file_name variables for readability. Let’s move on to making the HTTP request.
1 2 3 4 5 6 7 | print('Grabbing the page...') response = requests.get(url) response.raise_for_status() #TODO: Retrive all links on the page #TODO: Print links to text file |
On line 5, we are printing a message to the user so the user knows the program is working.
On line 6 we using the Requests library to make an HTTP get request using requests.get(url) and storing it in the response variable.
On line 7 we are calling the .raise_for_status() method which will return an HTTPError if the HTTP request returned an unsuccessful status code.
1 2 3 4 | soup = bs4.BeautifulSoup(response.text, 'html.parser') links = soup.find_all('a') #TODO: Print links to text file |
On line 1 we are calling bs4.BeautifulSoup() and storing it in the soup variable. The first argument is the response text which we get using response.text on our response object. The second argument is the html.parser which tells BeautifulSoup we are parsing HTML.
On line 2 we are calling the soup object’s .find_all() method on the soup object to find all the HTML a tags and storing them in the links list.
1 2 3 4 5 6 7 | file = open(file_name, 'wb') print('Collecting the links...') for link in links: href = link.get('href') + '\n' file.write(href.encode()) file.close() print('Saved to %s' % file_name) |
On line 1 we are opening a file in binary mode for writing(‘wb’) and storing it in the file variable.
On line 2 we are simply providing the user feedback by printing a message.
On line 3 we iterate through the links list which contains the links we grabbed using soup.findall(‘a’) and storing each link object in the link variable.
On line 4 we are getting the a tag’s href attribute by using .get() method on the link object and storing it in the href variable and appending a newline(\n) so each link is on its own line.
On line 5 we are printing the link to the file. Notice that were calling .encode() on the href variable, remember opened the file for writing in binary mode and therefore we must encode the string as a bytes-like object otherwise you will get a TypeError.
On line 6 we are closing the file with the .close() method and printing a message on line 7 to the user letting them know the processing is done. Now let’s look at the completed program and run it.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | #!venv/bin/python import sys import requests import bs4 if len(sys.argv) == 3: # If arguments are satisfied store them in readable variables url = 'http://%s' % sys.argv[1] file_name = sys.argv[2] print('Grabbing the page...') # Get url from command line response = requests.get(url) response.raise_for_status() # Retrieve all links on the page soup = bs4.BeautifulSoup(response.text, 'html.parser') links = soup.find_all('a') file = open(file_name, 'wb') print('Collecting the links...') for link in links: href = link.get('href') + '\n' file.write(href.encode()) file.close() print('Saved to %s' % file_name) else: print('Usage: ./collect_links.py wwww.example.com file.txt') |
Now all you
have to do is type this into the command line:
./collect_links.py www.intellignet-d2.com links.txt |
Output:
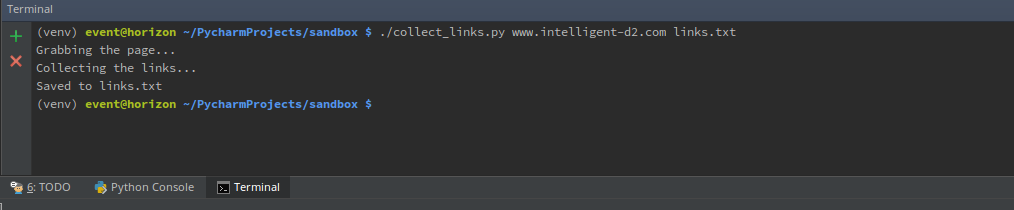
Now all you have to do is open up the links file in an editor to verify they were indeed written.
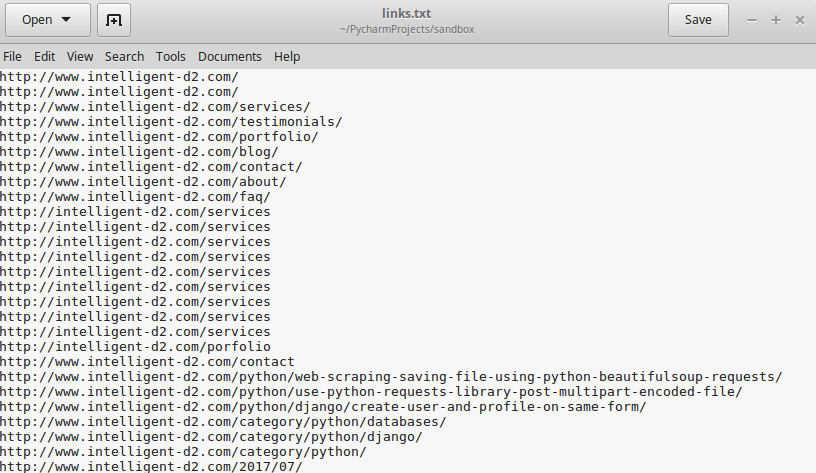
And that’s all there is to it. You have now successfully written a web scraper that saves links to a file on your computer. You can take this concept and easily expand it for all sorts of web data processing.
Further reading: Requests, BeautifulSoup, File I/O
Nice. Keep it up
Thanks!
Hi there, I just copied the code you wrote it… really cool code, and is working, actually I have the file.txt with all I want, but I’m getting TypeError: unsupported operand type(s) for +: ‘NoneType’ and ‘str’
Here is the code I have:
#!venv/bin/python
import sys
import requests
import bs4
if len(sys.argv) == 3:
# If arguments are satisfied store them in readable variables
url = ‘http://%s’ % sys.argv[1]
file_name = sys.argv[2]
print(‘Grabbing the page…’)
# Get url from command line
response = requests.get(url)
response.raise_for_status()
# Retrieve all links on the page
soup = bs4.BeautifulSoup(response.text, ‘html.parser’)
links = soup.find_all(‘a’)
file = open(file_name, ‘wb’)
print(‘Collecting the links…’)
for link in links:
href = link.get(‘href’) + ‘\n’
file.write(href.encode())
file.close()
print(‘Saved to %s’ % file_name)
else:
print(‘Usage: ./collect_links.py http://www.example.com file.txt’)
Any ideas ? I am really new to python
Hi there, I ‘ve modified in here:
href = “{0}\n”.format(link.get(“href”))
It’s SOLVED great article!!!!
So after investigating I found out what I did wrong. And the fix is simpler than your modification. On line 24
file.write(href)I forgot to encode the str to byte data since we’re opening the file in binary mode. Therefore all you have to do isfile.write(href.encode())and it will work. Thanks for pointing out this error. I have updated the article to include the fix.Hello sir
i have copied it and it will works only else portion.and open the code in text file that i compile
Can I see your code please? I’m having difficulty understanding you and what is specifically not working.
Every time I run the code it works else portion.opens your give code in text format. and I do not understand where I need to give my URL? and also how can i scrab data that I specify my given requirement,like not only link in a page,also p tag/h1 tag content
On line 17 it says: links = soup.find_all(‘a’).
That variable is where you select the HTML elements. You can change the name “links” to paragraphs, headers etc… and instead of find_all(‘a’), you can do find_all(‘p’) or (‘h1’) to grab the elements you’re interested.